|
I am a Research Fellow in the Department of Medical Physics at Memorial Sloan Kettering Cancer Center, working under the mentorship of Dr. Harini Veeraraghavan. My research focuses on applying machine learning to medical imaging to for enhancing clinical decision-making, with focus on for parameter-efficient and robust application of foundation models. I completed my PhD at The Chester F. Carlson Center for Imaging Science at Rochester Institute of Technology (RIT), advised by Dr. Matthew Hoffman and co-advised by Dr. Christopher Kanan and Dr. Emmett Ientilucci. Email / GitHub / Google Scholar / CV (PDF) |

|
|
|
|
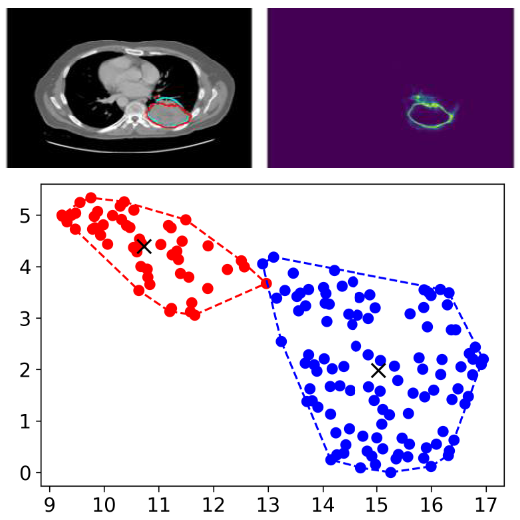
Aneesh Rangnekar, Harini Veeraraghavan arXiv We developed RF-Deep, a lightweight, plug-and-play OOD detector that improves the safety of automated tumor segmentation from 3D CT scans. It uses random forests on deep hierarchical features from the backbone of the segmentation model itself, without any modifications to the model, to identify imaging outliers. Across 1,916 scans, RF-Deep outperformed existing methods, achieving greater than 93.50 AUROC on two near-OOD datasets and near-perfect (99.0) AUROC on two far-OOD datasets. Its architecture-agnostic design ensures reliable performance across different networks, pretraining strategies, and imaging variations. |
|
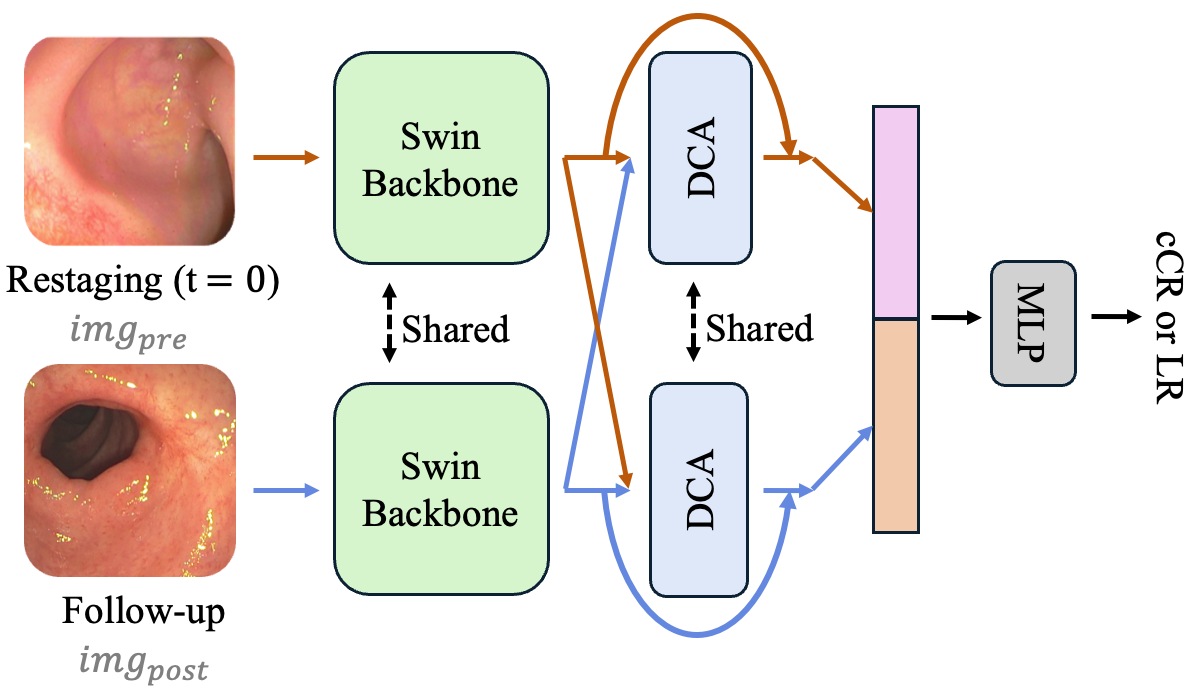
Jorge Tapias Gomez, Despoina Kanata, Aneesh Rangnekar, Christina Lee, Julio Garcia-Aguilar, Joshua Jesse Smith, Harini Veeraraghavan International Symposium on Biomedical Imaging (ISBI), 2026 arXiv We developed a new deep-learning model called SSDCA, which uses a Siamese Swin Transformer with dual cross-attention to compare endoscopic images taken at restaging and follow-up. The model identifies whether a patient has a clinical complete response (cCR) or early signs of local regrowth (LR). By using pretrained Swin Transformers, SSDCA focuses on meaningful features in the images without needing the scans to be perfectly aligned. In testing, it delivered the best performance and remained reliable even when images contained common endoscopic challenges such as blood, stool, telangiectasia, or poor image quality. |
|
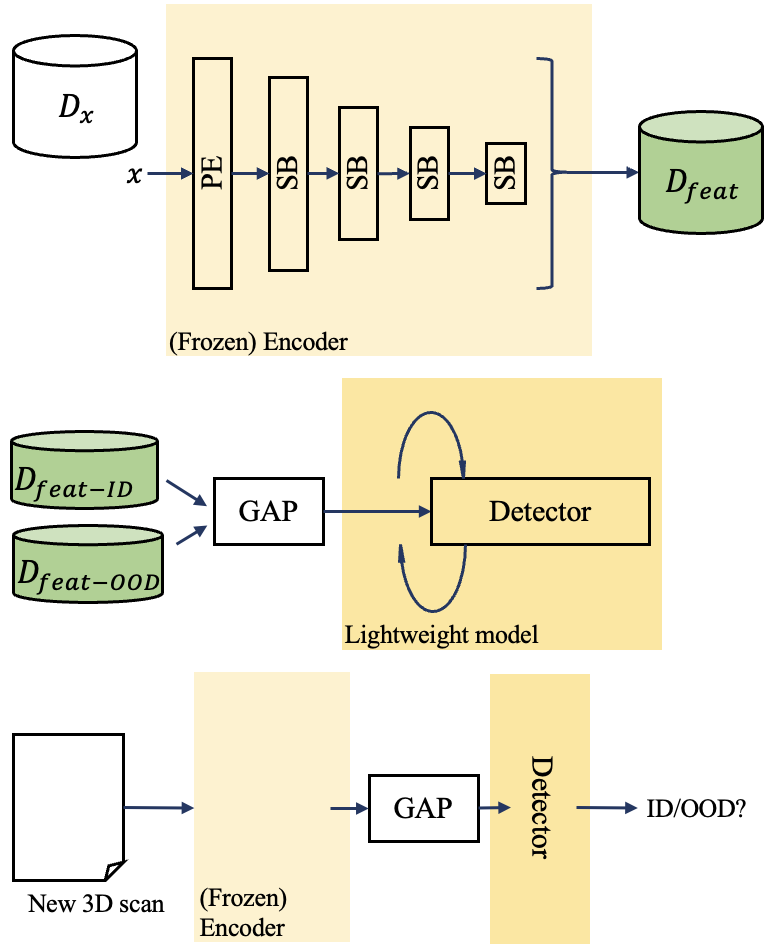
Aneesh Rangnekar, Harini Veeraraghavan SPIE Medical Imaging, 2026 arXiv Accurate detection and segmentation of cancerous lesions from computed tomography (CT) scans is essential for automated treatment planning and cancer treatment response assessment. We proposed RF-Deep, a random forest classifier that utilizes deep features from a pretrained transformer encoder of the segmentation model to detect OOD scans and enhance segmentation reliability. RF-Deep achieved strong detection performance (with FPR95 < 0.1% on far-OOD cases), outperforming established OOD approaches. |
|
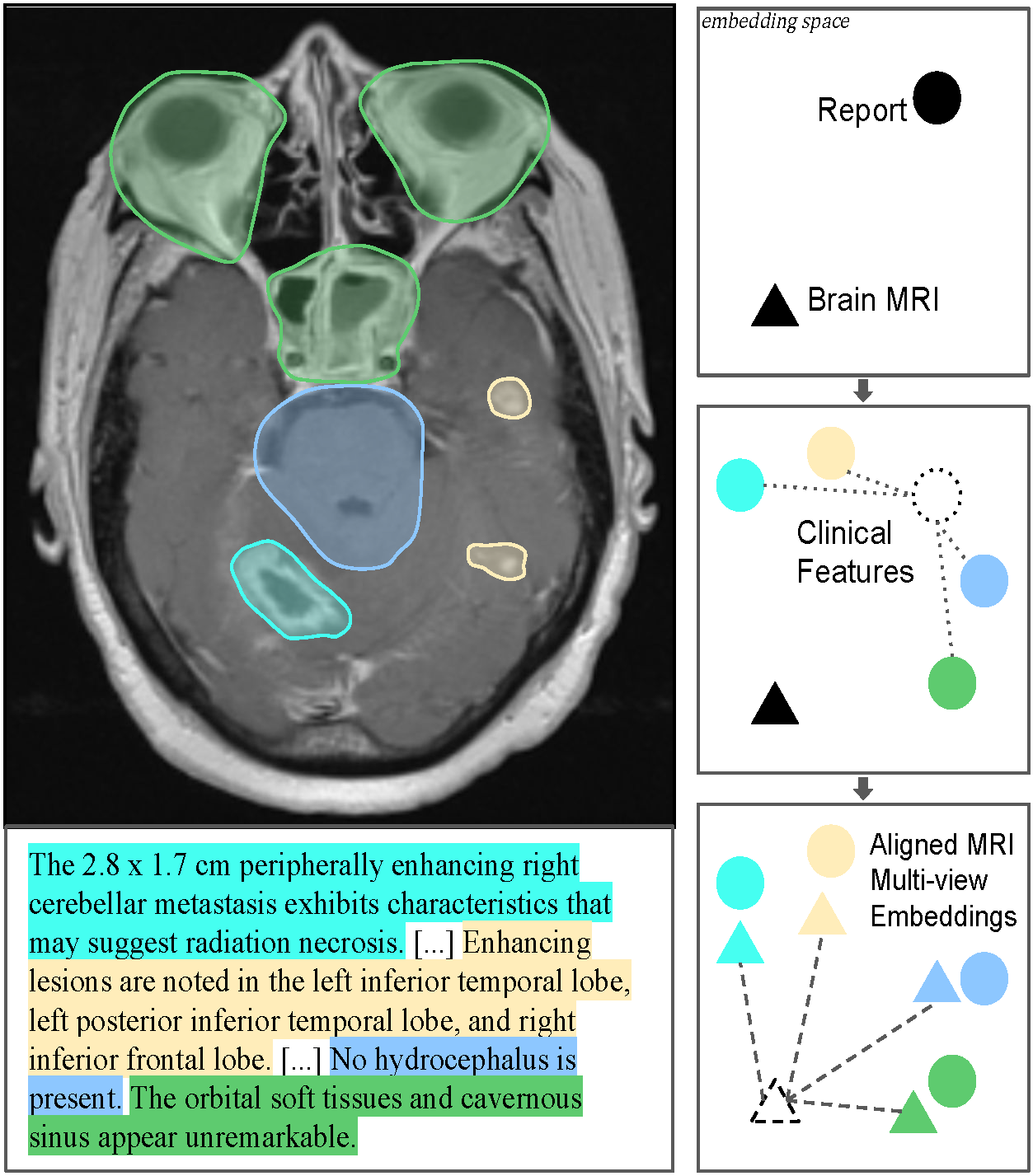
Maxime Kayser, Maksim Gridnev, Wanting Wang, Max Bain, Aneesh Rangnekar, Avijit Chatterjee, Aleksandr Petrov, Harini Veeraraghavan, Nathaniel C. Swinburne Winter Conference on Applications of Computer Vision (WACV), 2026 Paper We developed brat (Brain Report Alignment Transformer), trained on 75k MRI–report pairs with a pairwise view alignment and diversity-promoting loss. Leveraging these mechanisms, brat outperforms prior methods on image-text retrieval, tumor segmentation, and Alzheimer’s classification, and also enables high-quality automatic report generation from MRIs using language models. |
|
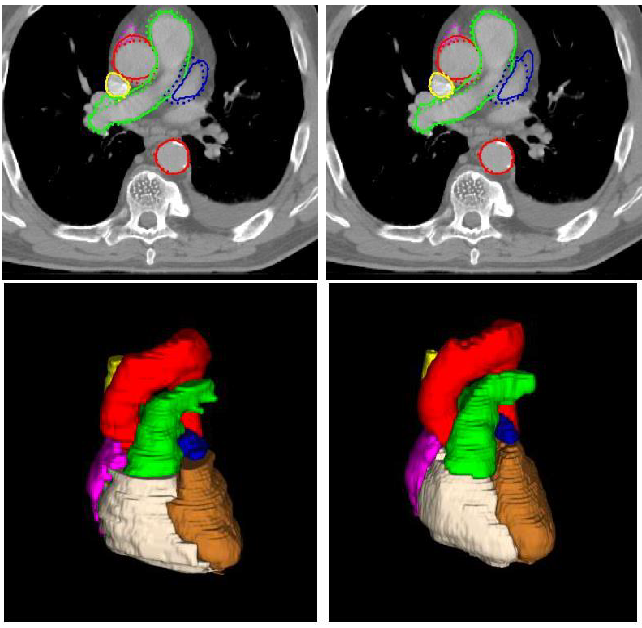
Aneesh Rangnekar, Nikhil Mankuzhy, Jonas Willmann, Chloe Choi, Abraham Wu, Maria Thor, Andreas Rimner, Harini Veeraraghavan arXiv We fine-tuned a pretrained transformer with a convolution decoder for cardiac substructures segmentation in contrast and non-contrast CT scans, with an emphasis on reducing the need for extensive annotated data. Pretrained on large in-the-wild CT dataset, the model was adapted for radiotherapy planning in lung cancer patients, with zero-shot application on breast cancer patients. Extensive experiments demonstrated strong generalization across imaging modalities, clinical sites, and patient positioning. |
|
Jue Jiang, Aneesh Rangnekar, Harini Veeraraghavan Medical Physics, 2025 arXiv / Publication We investigated the benefits of large-scale in-the-wild self-supervised pretraining on uncurated CT scans to improve robustness in tumor segmentation, with a focus on lung cancer tumors. When fine-tuned on smaller curated NSCLC datasets, Swin transformer models pretrained on this diverse unlabeled data, consistently outperformed both self-pretrained Swin and Vision Transformer counterparts across varied CT acquisition protocols. Our study directly addresses whether self-supervision on noisy, heterogeneous CT data improves generalization to real-world distribution shifts — a critical gap underaddressed by prior research. |
|
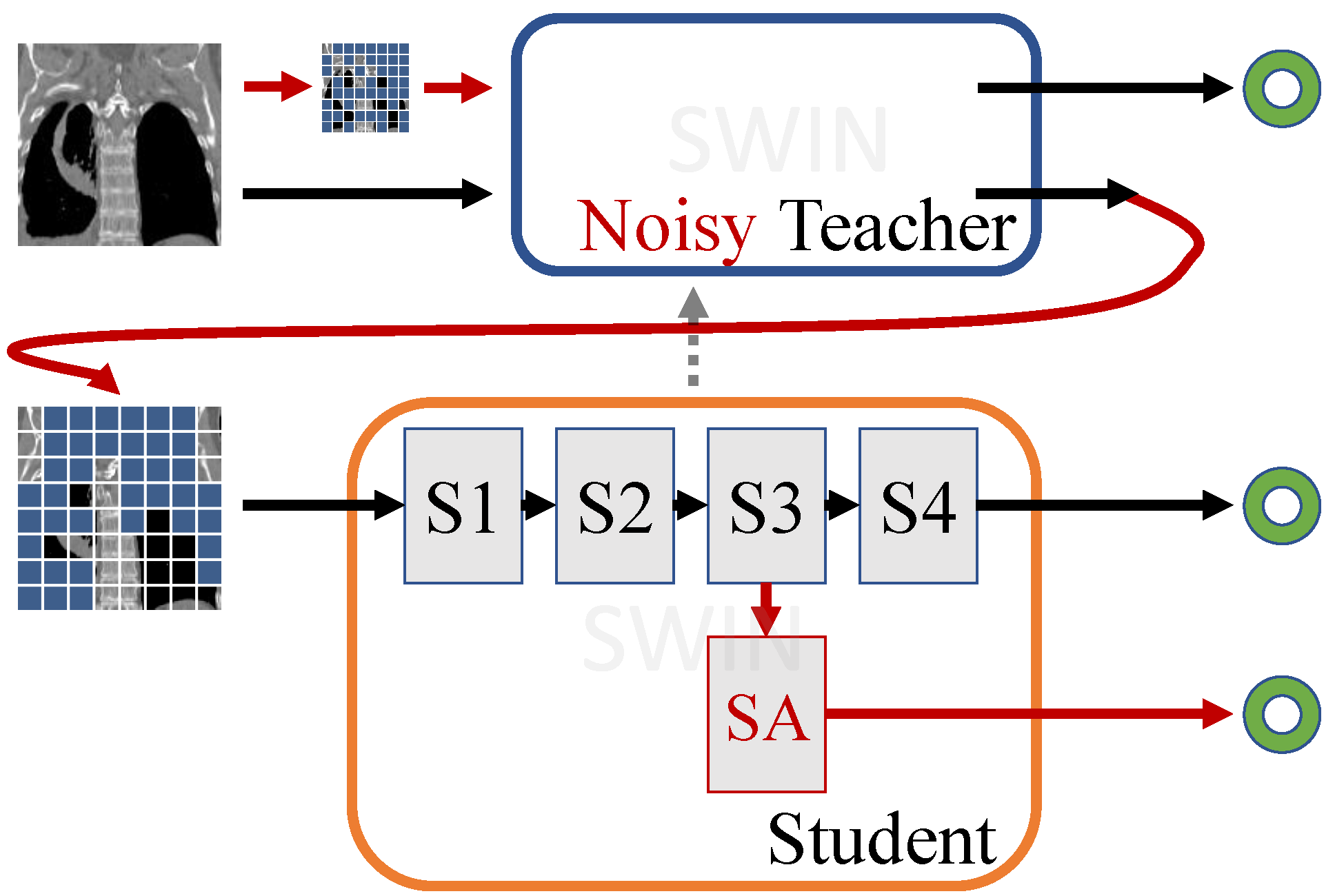
Jue Jiang, Aneesh Rangnekar, Harini Veeraraghavan Medical Imaging with Deep Learning, 2025 Paper / OpenReview We developed DAGMaN, a novel self-supervised learning framework that combined attention-guided masked image modeling and noisy teacher co-distillation for medical imaging. We integrated global semantic attention into Swin transformers with vision transformer based multi-head self-attention blocks, and improved feature learning and attention diversity by noise injection in the teacher’s pipeline. Our approach outperformed prior methods on multiple medical tasks and achieved high accuracy in few-shot settings, while enabling better interpretability via attention map visualization, a previously unavailable feature for Swin transformers. |
|
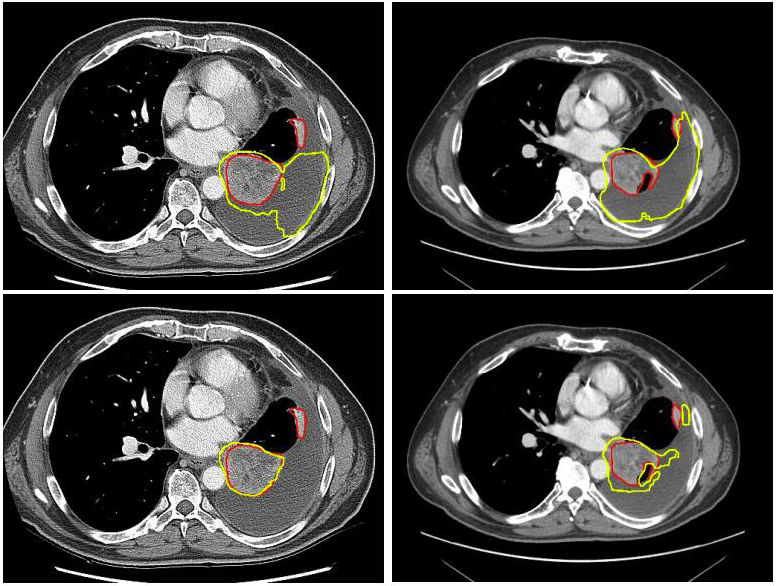
Aneesh Rangnekar, Nishant Nadkarni, Jue Jiang, Harini Veeraraghavan SPIE Medical Imaging, 2025 arXiv / Publication We investigated applications of foundation models on lung tumor segmentation across mixed-domain CT datasets, encompassing diverse acquisition protocols and institutions, as a stepping stone towards task generalization. Our study evaluated segmentation performance and uncertainty estimation using Monte Carlo dropout, deep ensembles, and test-time augmentation. We demonstrated that fast, entropy-based metrics and volumetric occupancy can effectively track model performance under domain shift, offering introductory practical tools to evaluate segmentation trustworthiness in mixed-domain clinical settings. |
|
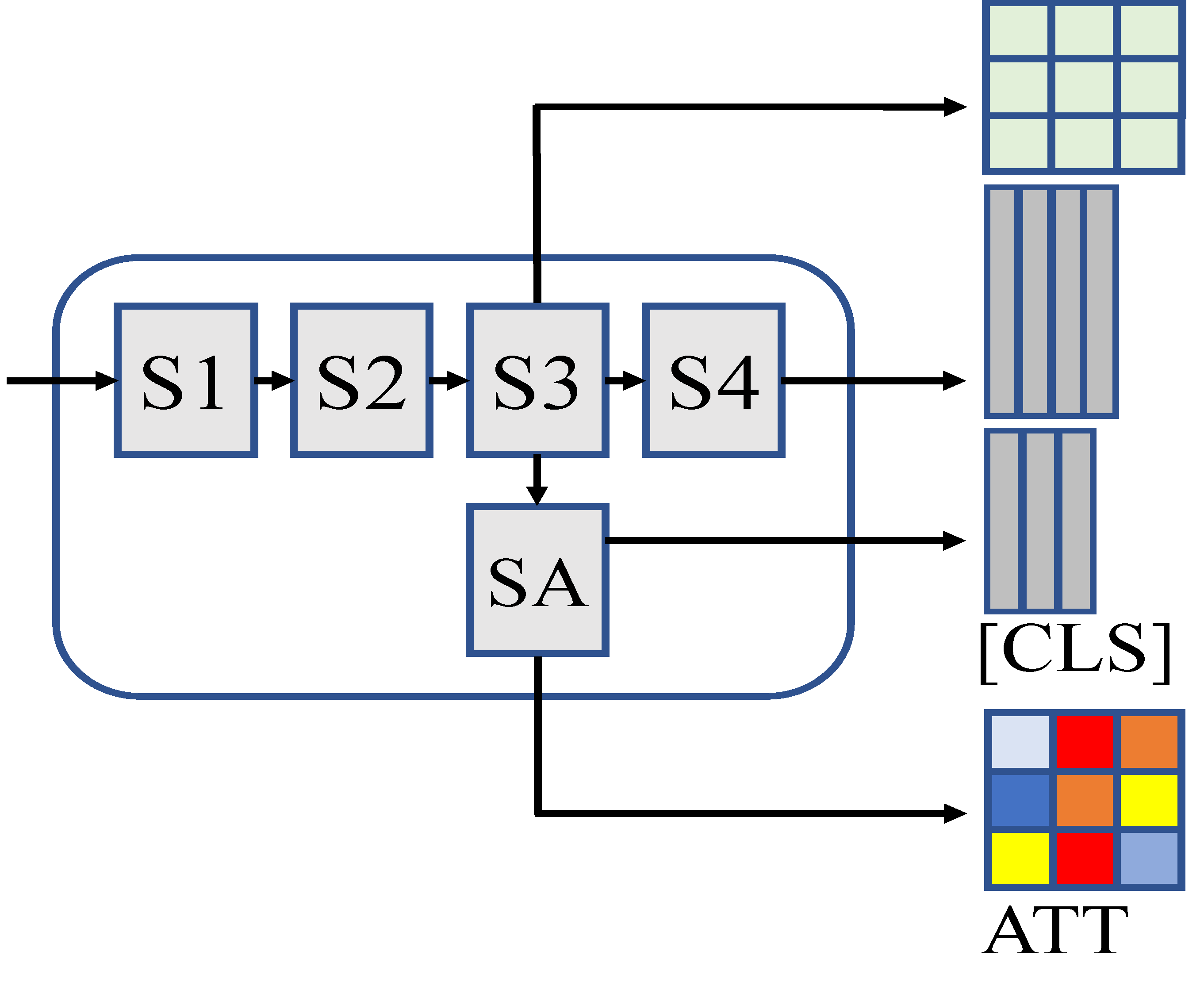
Jue Jiang, Aneesh Rangnekar, Chloe Choi, Harini Veeraraghavan arXiv / AAPM 2024 SNAP Oral We developed a new self-supervised framework for medical imaging with Swin Transformers, which traditionally lack the [CLS] token used with masked image modeling. We introduced a semantic attention module for global masking and a noise-regularized momentum teacher for stable co-distillation. This yielded a stronger foundation model, improving tumor/organ segmentation and enabling zero-shot localization via [CLS] global attention maps. |
|
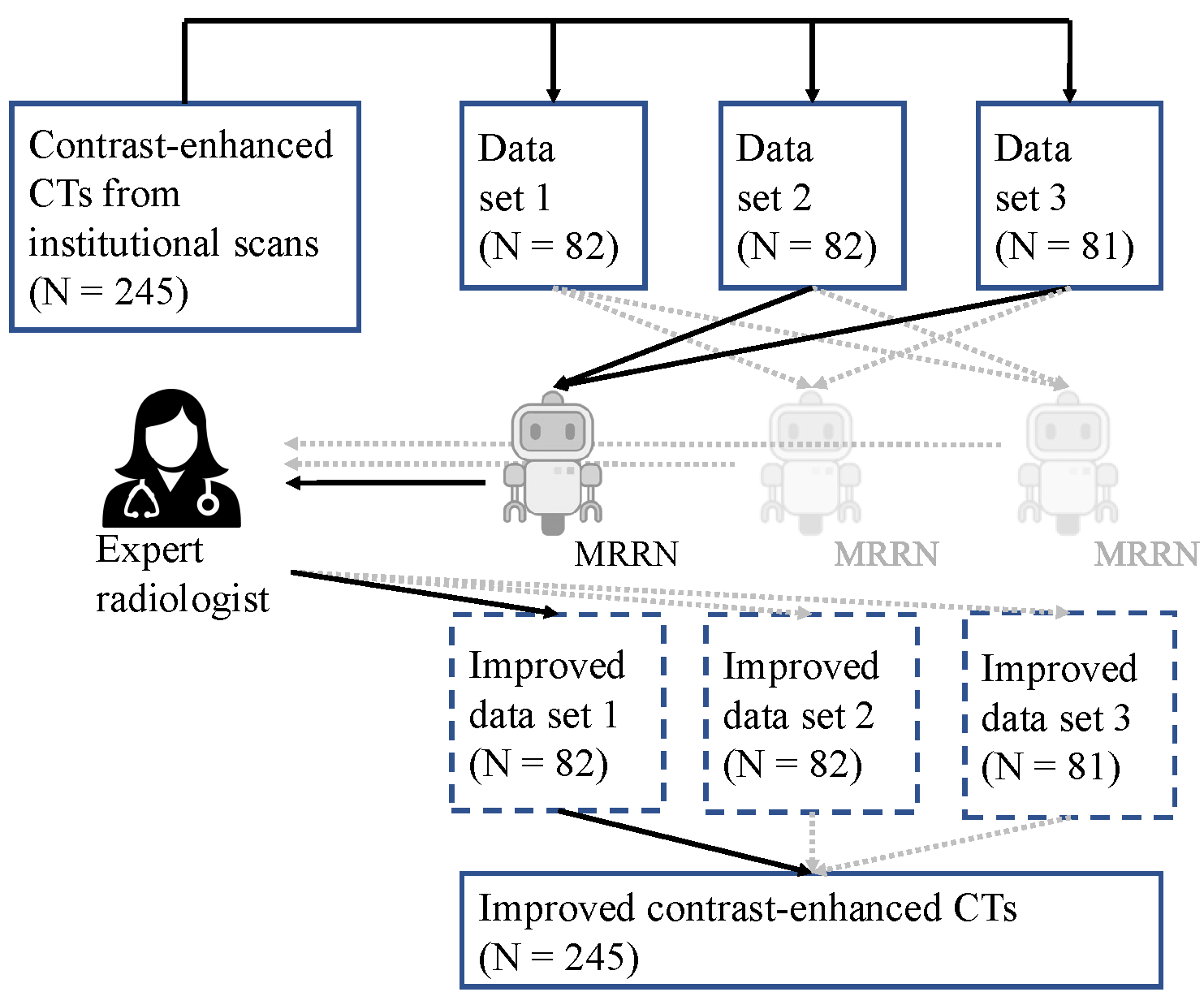
Aneesh Rangnekar, Kevin M. Boehm, Emily A. Aherne, Ines Nikolovski, Natalie Gangai, Ying Liu, Dimitry Zamarin, Kara Roche, Sohrab Shah, Yulia Lakhman, Harini Veeraraghavan arXiv We formulated an AI-guided labeling pipeline using a multi-resolution residual 2D network trained on partially segmented CTs (adnexal tumors and omental implants) to assist radiologists in refining annotations. The enhanced dataset fine-tuned two transformer architectures, namely SMIT and Swin UNETR, and is evaluated across 71 multi-institutional 3D CT scans. Training with AI-refined labels yielded statistically significant improvements across all metrics for both models. Our approach emphasized efficient dataset curation, reducing annotation workload for radiologists while improving model performance and radiomics reproducibility in ovarian cancer. |
|
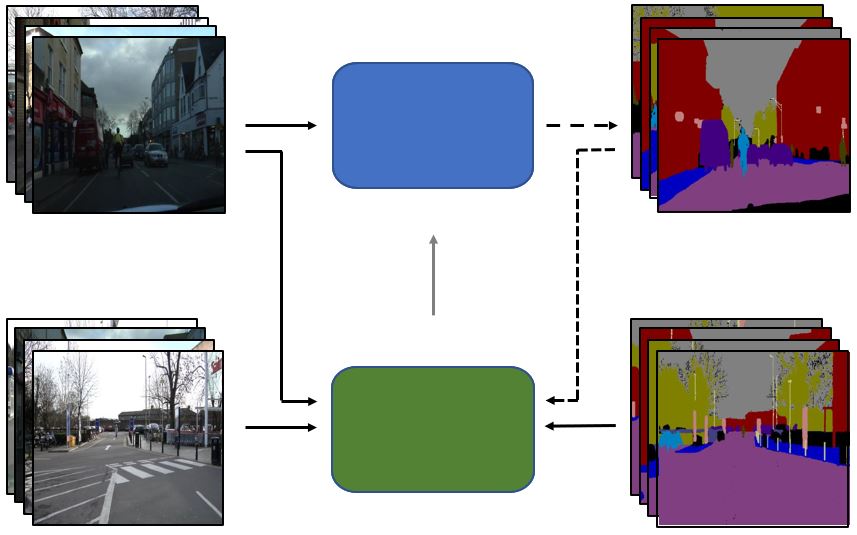
Aneesh Rangnekar, Christopher Kanan, Matthew Hoffman Winter Conference on Applications of Computer Vision (WACV), 2023 arXiv / Publication / Code / Poster / Presentation We developed S4AL, a hybrid approach that combined semi-supervised and active learning, for data-efficient semantic segmentation. It uses a teacher–student pseudo-labeling framework to generate region-level acquisition scores, enabling querying and annotating of only the most informative regions rather than full images. We introduced two regularization techniques, confidence weighting and balanced ClassMix, that helped mitigate class imbalance and enhance quality of the acquisition metric. S4AL achieved over 95% of full-dataset performance using less than 17% of pixel annotations on CamVid and CityScapes datasets. |

|
Aneesh Rangnekar, Christopher Kanan, Matthew Hoffman British Machine Vision Conference (BMVC), 2022 arXiv / Publication / Poster / Presentation We developed S4AL+, a hybrid framework that combines semi-supervised learning with active learning for semantic segmentation, aiming to reduce annotation costs. We replaced the conventional mean-teacher approach with self-training using noisy pseudo-labels and added a contrastive head for better feature learning of the classes. On benchmarks CamVid and CityScapes, S4AL+ achieved over 95% of full-label performance using just 12–15% of labeled data, outperforming state-of-the-art approaches at the time. |

|
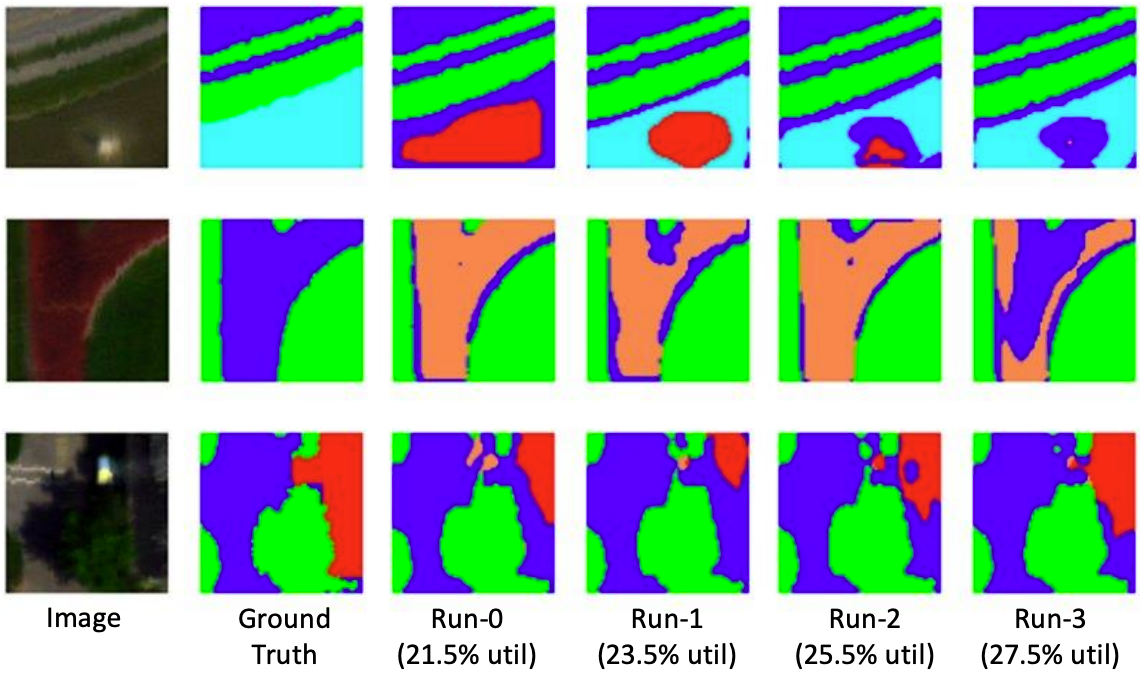
Aneesh Rangnekar, Zachary Mulhollan, Anthony Vodacek, Matthew Hoffman, Angel Sappa, Erik Blasch, et al. Computer Vision and Pattern Recognition (CVPR) workshops, 2022 Publication We curated the first true hyperspectral object detection dataset, collected from a university rooftop overlooking a 4-way intersection over three days. The dataset consists of 2890 temporally contiguous frames at ~1600×192 resolution, spanning 51 spectral bands from 400–900nm. To capture real-world variability, the training, validation, and test datasets were acquired on different days under varying weather conditions. Labels are provided for both fully-supervised and semi-supervised settings, encouraging a competition hosted at CVPR Perception Beyond the Visible Spectrum workshop. |
|
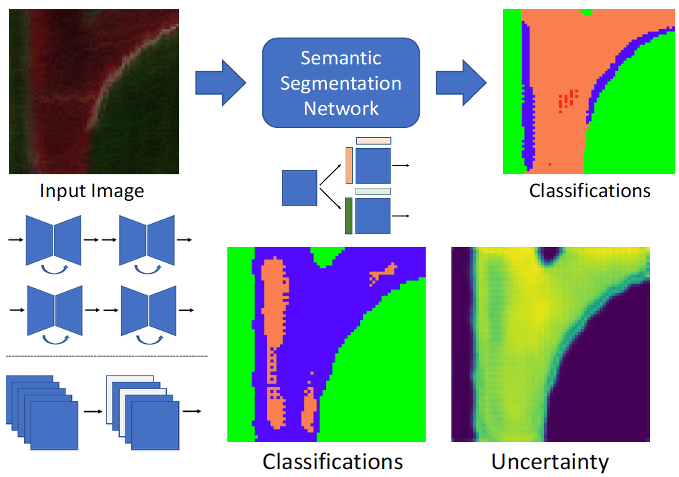
Aneesh Rangnekar, Emmett Ientilucci, Christopher Kanan, Matthew Hoffman Dynamic Data Driven Applications Systems (DDDAS), 2022 Paper / Publication We proposed SpecAL, an active learning framework for semantic segmentation of hyperspectral imagery, reducing the need for extensive efforts for labeled data. Using the AeroRIT dataset, we combine data-efficient neural network design with self-supervised learning and batch-ensembles based uncertainty acquisition to iteratively improve performance. Our method design achieved oracle level segmentation performance using only 30% of the labeled data, demonstrating a scalable path for annotation-efficient hyperspectral analysis. |
|
Aneesh Rangnekar, Emmett Ientilucci, Christopher Kanan, Matthew Hoffman Dynamic Data Driven Applications Systems (DDDAS), 2020 Paper / Publication We extended deep learning for hyperspectral imaging on the AeroRIT dataset by evaluating network uncertainty within a Dynamic Data-Driven Applications Systems (DDDAS) framework. Using Deep Ensembles, Monte Carlo Dropout, and Batch Ensembles with a modified U-Net, we studied robust pixel-level segmentation under noisy, atmosphere-sensitive signals. Our results highlighted uncertainty estimation as key to guiding resource allocation and improving hyperspectral semantic segmentation. |

|
Aneesh Rangnekar, Nilay Mokashi, Emmett Ientilucci, Christopher Kanan, Matthew Hoffman Transactions on Geoscience and Remote Sensing (TGRS), 2020 arXiv / Publication / Code We introduced AeroRIT, a new aerial hyperspectral dataset designed specifically to support convolutional neural network (CNN) training for scene understanding. Unlike typical airborne hyperspectral datasets focused on vegetation or roads, AeroRIT includes buildings and cars, expanding the domain diversity. ed and benchmarked several CNN architectures on AeroRIT, thoroughly evaluating classification accuracy, spatial consistency, and generalization across scenes. |

|
Burak Uzkent, Aneesh Rangnekar, Matthew Hoffman Transactions on Geoscience and Remote Sensing (TGRS), 2018 arXiv / Publication We developed DeepHKCF, a hyperspectral aerial vehicle tracker that combines kernelized correlation filters (KCFs) with deep CNN features, leveraging adaptive multimodal hyperspectral sensors. A single KCF-in-multiple-ROIs strategy with efficient ROI mapping addresses low temporal resolution while enabling fast feature extraction and flexibility to integrate advanced correlation filter trackers. Experiments on DIRSIG-simulated hyperspectral videos show strong tracking performance, along with a released large-scale synthetic dataset for vehicle classification in wide-area motion imagery (WAMI). |

|
Burak Uzkent, Aneesh Rangnekar, Matthew Hoffman Computer Vision and Pattern Recognition (CVPR) workshops, 2017 arXiv / Publication We developed hyperspectral likelihood maps-aided tracking (HLT), a real-time hyperspectral tracking method that learns a generative target model online without offline classifiers or heavy hyperparameter tuning. It adaptively fuses likelihood maps across visible-to-infrared bands into a distinctive representation that separates foreground from background. Experiments show HLT outperforms existing fusion methods and matches state-of-the-art hyperspectral tracking frameworks. |
|
Last updated: 26th February 2026 / This website is adapted from Jon Barron's template (site, source code) |